Three system-level curves moved at once. Neutral-atom gates became more accurate and sustainable. Quantum error correction started to resemble a platform capability.
Randomness amplification entered the laboratory.
0. Takeaways
Neutral-atom gates are moving from peak fidelity toward sustained operation. QEC experiments now test platform-level capabilities such as code breadth, qubit reload, and memory density. Randomness amplification offers the clearest near-term bridge from these hardware advances to publicly verifiable digital infrastructure.
1. Introduction
Quantum computing news has a familiar rhythm: more qubits, another nine in the fidelity figure, and a closing line about being one step closer to fault-tolerant quantum computing.
After a while, very different results can begin to sound like the same announcement.
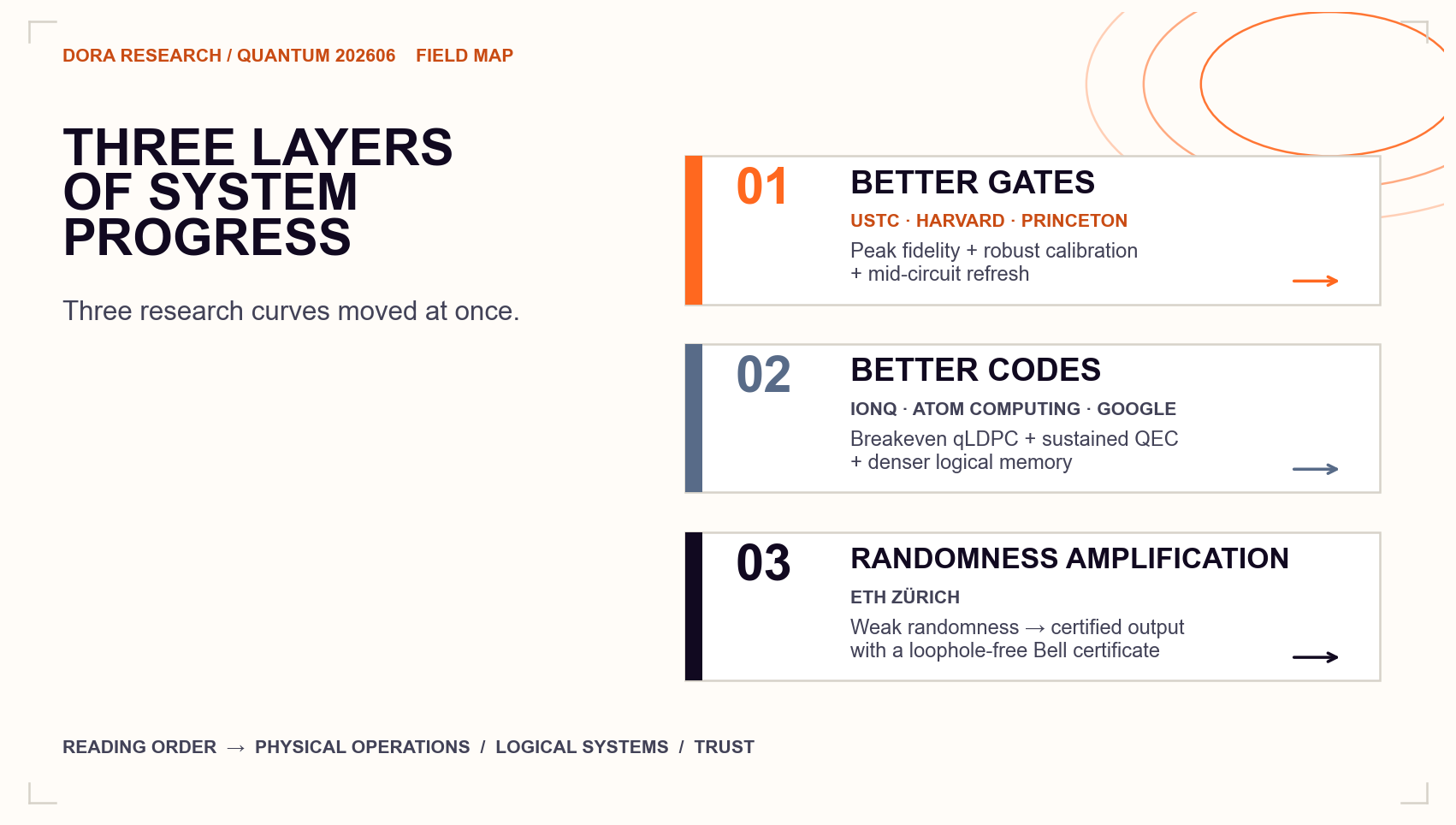
This batch of papers becomes more informative when read together. Each result fills in a different layer that a useful quantum computer will need:
- Gate accuracy must persist inside deep circuits.
- Quantum error correction must repeat, scale, and justify its overhead.
- Quantum outputs become more useful when they carry an auditable certificate.
This newsletter follows three threads and skips the usual “paper of the week” framing. They are better gates for neutral atoms, better codes across several hardware platforms, and randomness amplification. The final thread has the clearest connection to the trust problems of web3.
2. Better Gates for Neutral Atoms
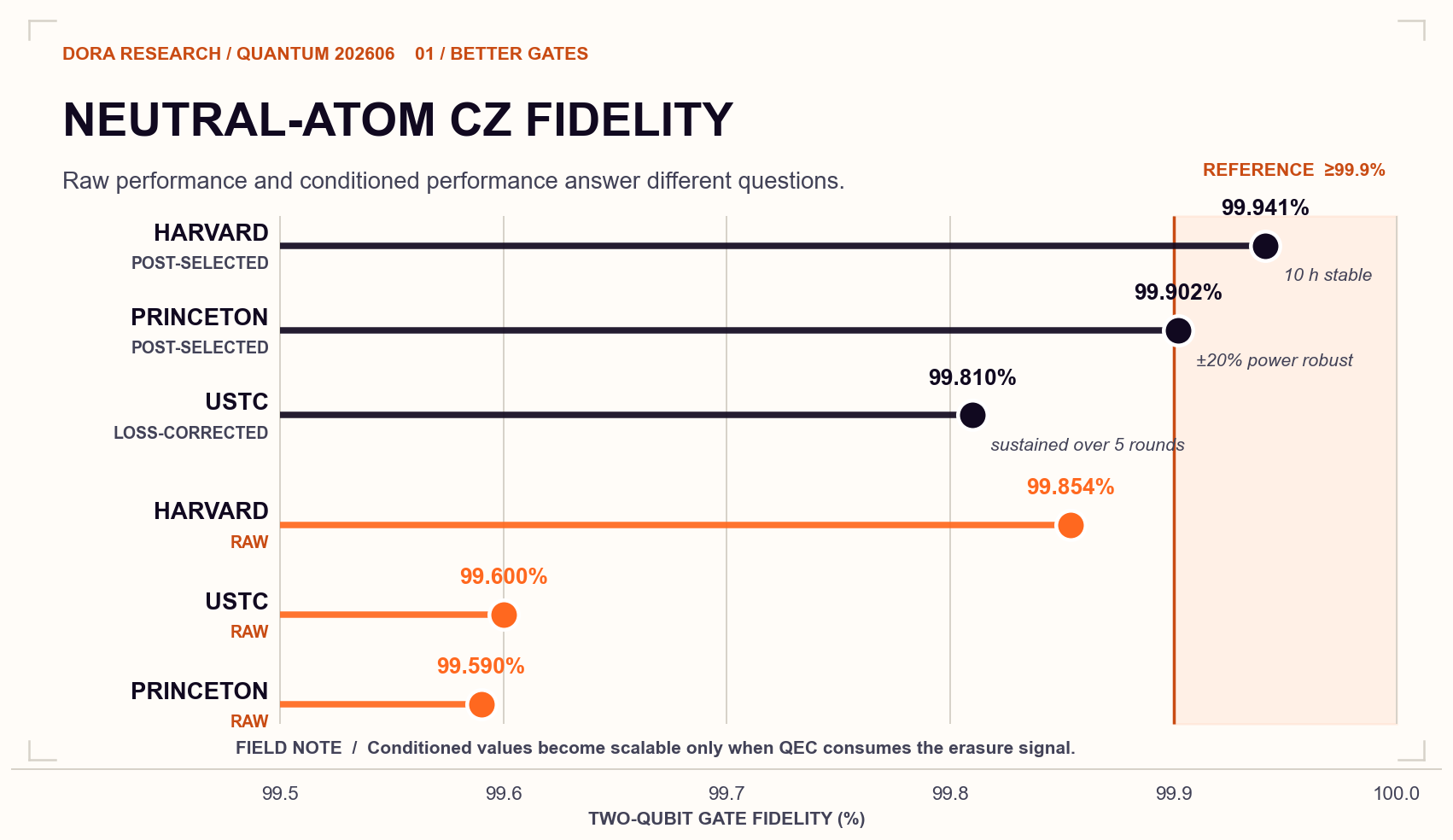
Neutral-atom two-qubit gates are approaching an important operating region. An error rate around or below 0.1% is commonly treated as a useful engineering target for efficient quantum error correction. The three spring 2026 papers reach this region through complementary advances.
Harvard reports the highest headline fidelity, reaching 99.941(3)% after post-selection. Princeton reaches 99.902(7)% after post-selection while remaining robust to ±20% laser-power variation. USTC sustains approximately 99.8% loss-corrected fidelity acrossfive rounds by adding mid-circuit maintenance. The comparison below separates raw resultsfrom conditioned results because the two values describe different operating assumptions.
Harvard: pushing peak CZ fidelity to 99.941%
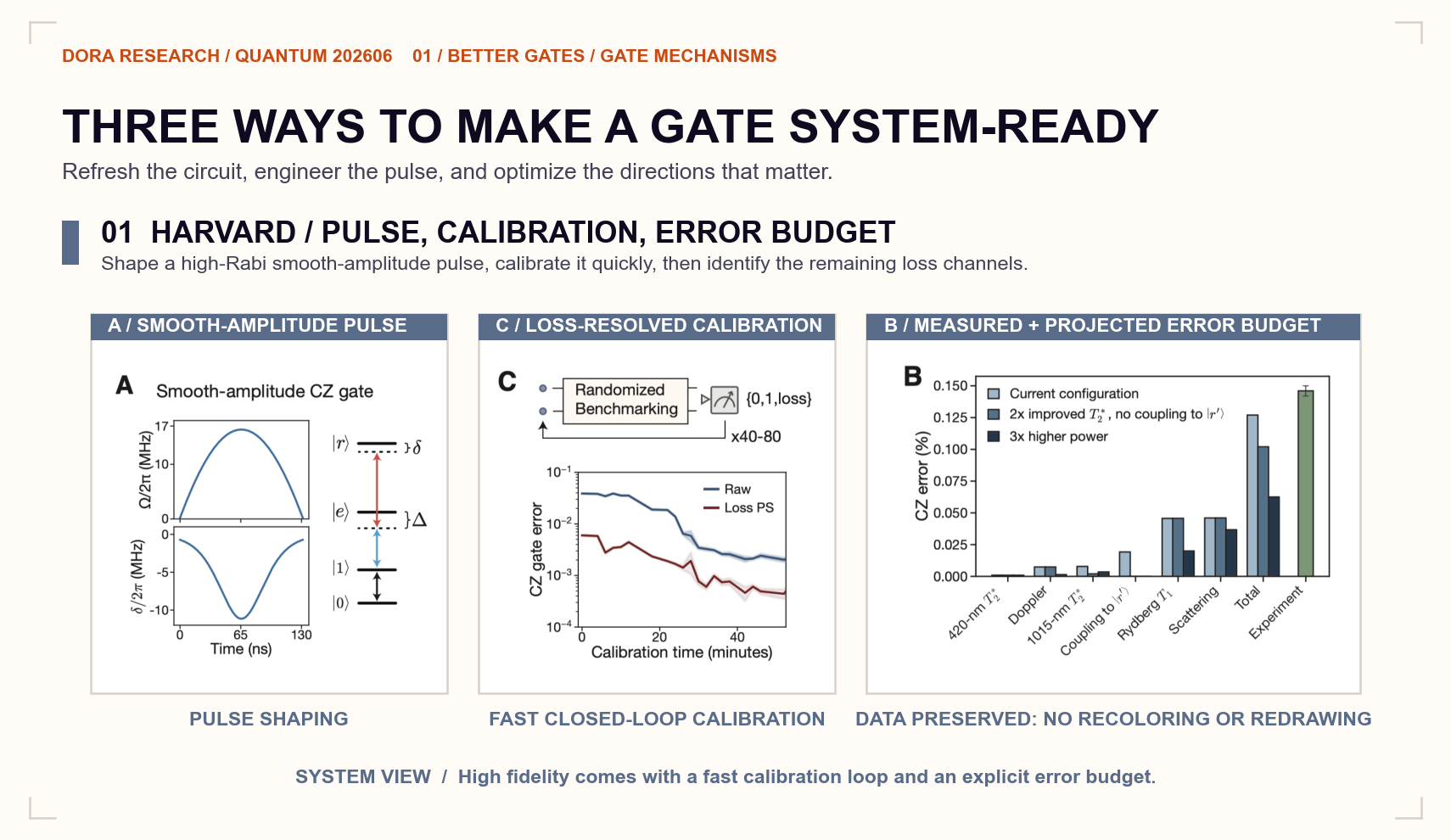
The Harvard/Lukin, MIT, and QuEra collaboration reports the highest headline fidelity. Its neutral-atom CZ gate reaches 99.854(4)% raw fidelity and 99.941(3)% afterpost-selection on atom survival. The performance remained stable for ten hours.[2]
The engineering combination behind the result matters as much as the record itself. The experiment uses a high-Rabi-frequency smooth-amplitude pulse, state-selective readout, and qubit reuse to accelerate calibration. The team pairs a strong pulse with a faster loop for finding, testing, and maintaining it.
The 99.941% value is conditioned on atom survival, so shots containing loss are excluded. A fault-tolerant system must identify that loss during operation, represent it as an erasure, and pass the information to the decoder.
Princeton: turning calibration into a system capability
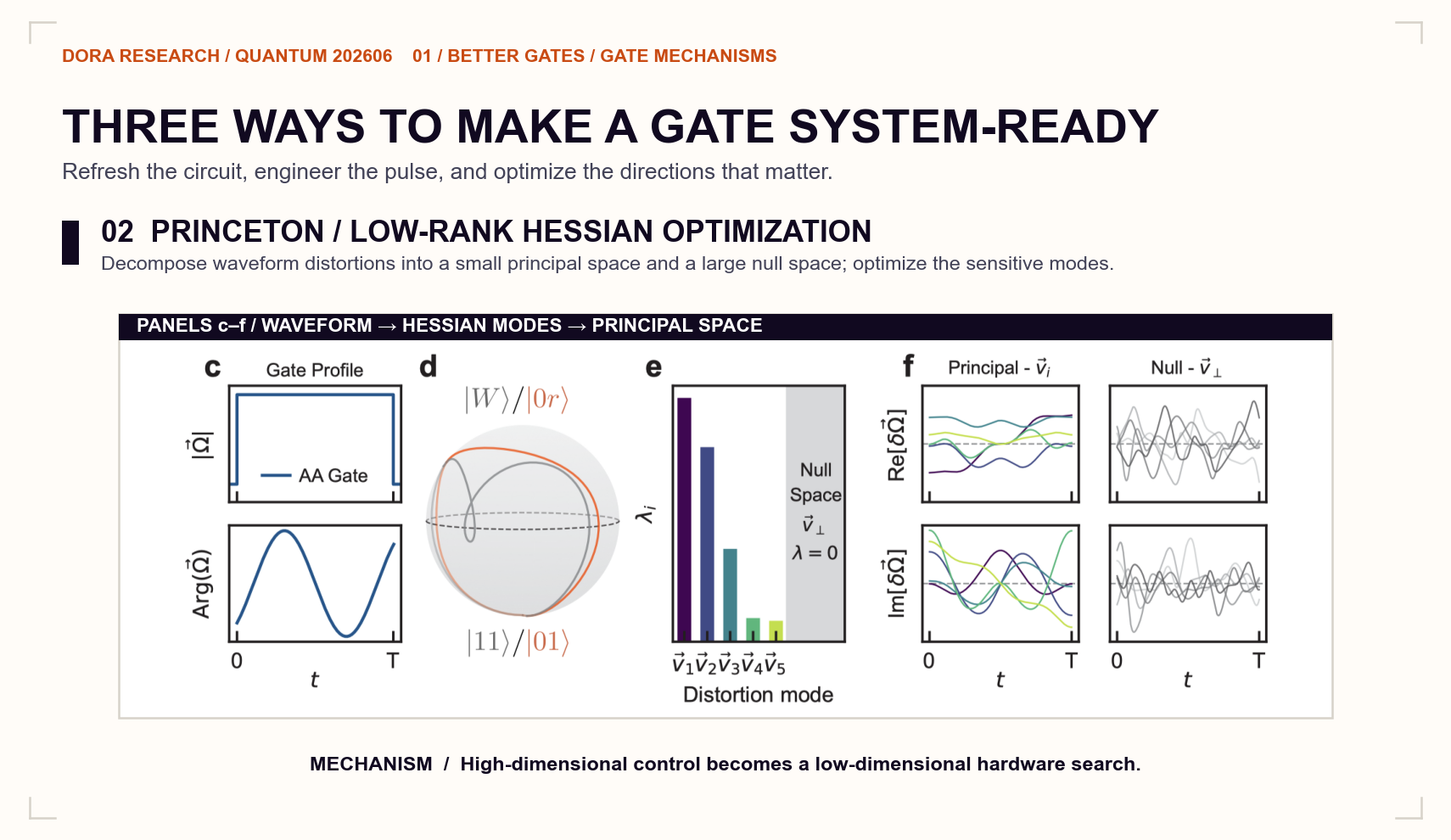
The Princeton/Thompson experiment on Yb-171 addresses a different practical problem. Optimal-control waveforms can have many parameters, making direct hardware calibration slow and sensitive to drift.[3]
The team uses a low-rank Hessian to identify the small number of principal directions that materially affect gate fidelity. It then performs closed-loop optimization within that reduced space. The resulting CZ gate reaches 99.59(2)% raw fidelity and 99.902(7)% after post-selection. Its performance also remains essentially unchanged under laser-power variations of up to ±20%.
That kind of robustness is particularly valuable at scale. A single atom-pair benchmark establishes peak performance. A diagnosable, low-maintenance calibration workflow turns that performance into a reusable engineering asset.
USTC: keeping high fidelity alive through the next round
The USTC/Pan-Lu work asks the most operational question of the three. Even when the first gate is good, motional heating and atom loss accumulate during repeated circuits and eventually pull fidelity down.[1]
The experiment integrates loss-resolved mid-circuit measurement, Raman sideband cooling, and qubit re-initialization between rounds. It reports a CZ fidelity of 99.60(1)% raw and 99.81(1)% loss-corrected, while sustaining approximately 99.8% loss-corrected performance across five rounds without observable degradation.
The paper adds a sustainability layer: detect loss, remove entropy, cool the atoms, and reset the qubits while the circuit is still running. Repeated syndrome extraction depends on this operational layer alongside high gate fidelity.
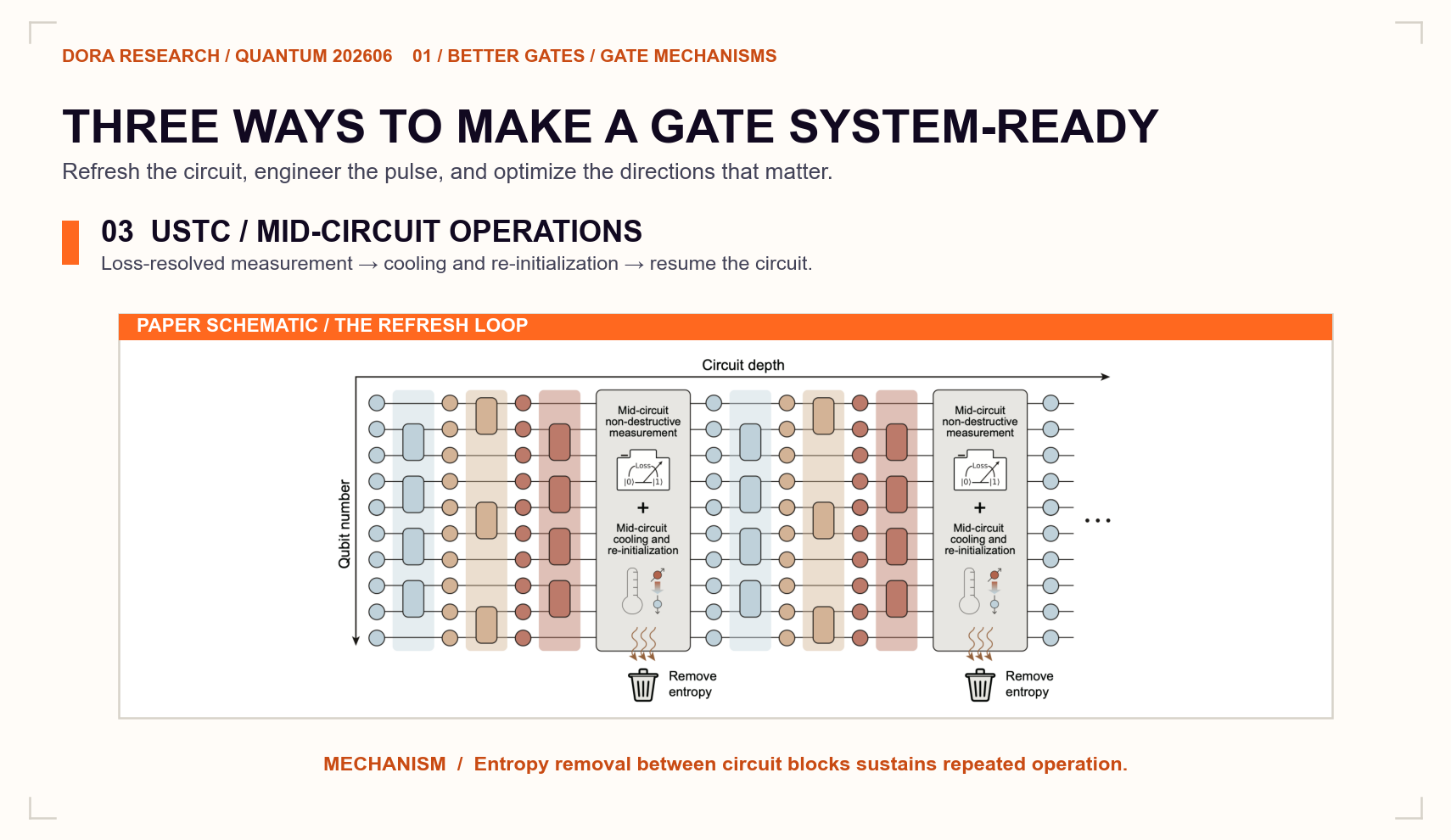
Three papers, three parts of the same machine
Harvard improves peak fidelity. Princeton reduces calibration complexity and sensitivity to drift. USTC manages entropy and loss during repeated operation. Together, they suggest that neutral-atom gate competition now includes peak performance, calibration resilience, and sustained circuit operation.
The black points in the comparison require careful interpretation. Loss-corrected and post-selected fidelities become scalable advantages when the erasure signal is available in real time and integrated into the QEC stack.
3. Better Codes
If physical gates are the foundation, an error-correcting code determines how much structure must be built on top of them. It controls the qubit overhead, connectivity requirements, logical lifetime, and ultimately whether the machine can run a useful algorithm economically.
Recent results from IonQ, Atom Computing, and Google attack different parts of that problem. Together, they show how each platform is trying to convert a physical advantage into a logical one.
IonQ: nine codes on one machine
IonQ implements nine error-correcting codes on the same stationary chain of forty Ba-133 ions. The experiments span qLDPC, topological, and concatenated code families without requiring a hardware reconfiguration for each connectivity graph.[4]
This is where all-to-all ion connectivity becomes more than a product specification. Many qLDPC codes are attractive in theory because of their high encoding rates, but their non-local checks are difficult to implement on locally connected hardware. IonQ turns connectivity into a code portfolio.
The strongest qLDPC result is the BB[[18,4,3]] code, with logical error per cycle of 1.08±0.80% for Z and 2.01±0.60% for X. Those values are roughly 4-9× lower than a previous superconducting demonstration of a comparable BB code. Most of the nine codes also achieve logical lifetimes comparable, within uncertainty, to the best physical qubit. That places the experiment in the breakeven regime.
Clean below-threshold scaling remains open. The larger BB[[30,4,5]] code has no automatic absolute-error advantage, and the experiment post-selects leakage. The most accurate summary is therefore breadth plus breakeven. A broader qLDPC victory would require stronger scaling evidence.
Atom Computing: reaching the 90th QEC cycle
For neutral atoms, loss is a structural challenge. Atom Computing keeps the computation running after an atom disappears. Its toric-code experiment combines mid-circuit measurement, role swapping, atom replacement, and reservoir reloading.[5]
The system performs syndrome extraction for as many as 90 cycles. In a shorter-distance comparison, the larger det16 variant gives a lower no-reload Z logical error rate: 0.56(1)% per cycle, compared with 0.74(1)% for det8. The repetition-code memory result is even more intuitive. Logical lifetime rises from 44(1) seconds at d=3 to 225(33) seconds at d=7. Individual physical atoms last roughly ten seconds.
The central result is an operations layer for neutral-atom QEC: find a missing qubit, supply another atom, and continue. This capability supports long runs even when the single-cycle error remains above the field's best values.
Google: packing more logical memory onto the same hardware
The Google Quantum AI paper focuses on architecture and resource estimates.[6] It keeps a regular two-dimensional hexagonal grid and nearest-neighbor operations. Twist defects, compact patch layouts, and yoking raise the estimated encoding rate to as much as 4.5× that of a rotated surface-code patch.
In simple terms, yoking allows many inner patches to share lower-frequency outer checks.
Those global checks catch rare failures, allowing each inner patch to be smaller for a given target reliability. The trade-off is access latency. The resulting architecture looks less like a uniform memory and more like fast hot memory paired with dense coldmemory.
Under the paper's assumptions, the architecture reduces the resource estimate for a FeMoco phase-estimation calculation to about 89,000 physical qubits. The estimated runtime is less than one month. The best physical quantum volume is approximately 1.3 mega-qubit-hours.
These simulated resource estimates assume 10^-3 gate-level depolarizing noise, a 1 μs surface-code cycle, a 10 μs reaction time, and favorable decoding and scheduling.
Hardware validation remains future work. The paper still shows how code density, memory hierarchy, decoding, and scheduling can reshape the Q-day resource curve.
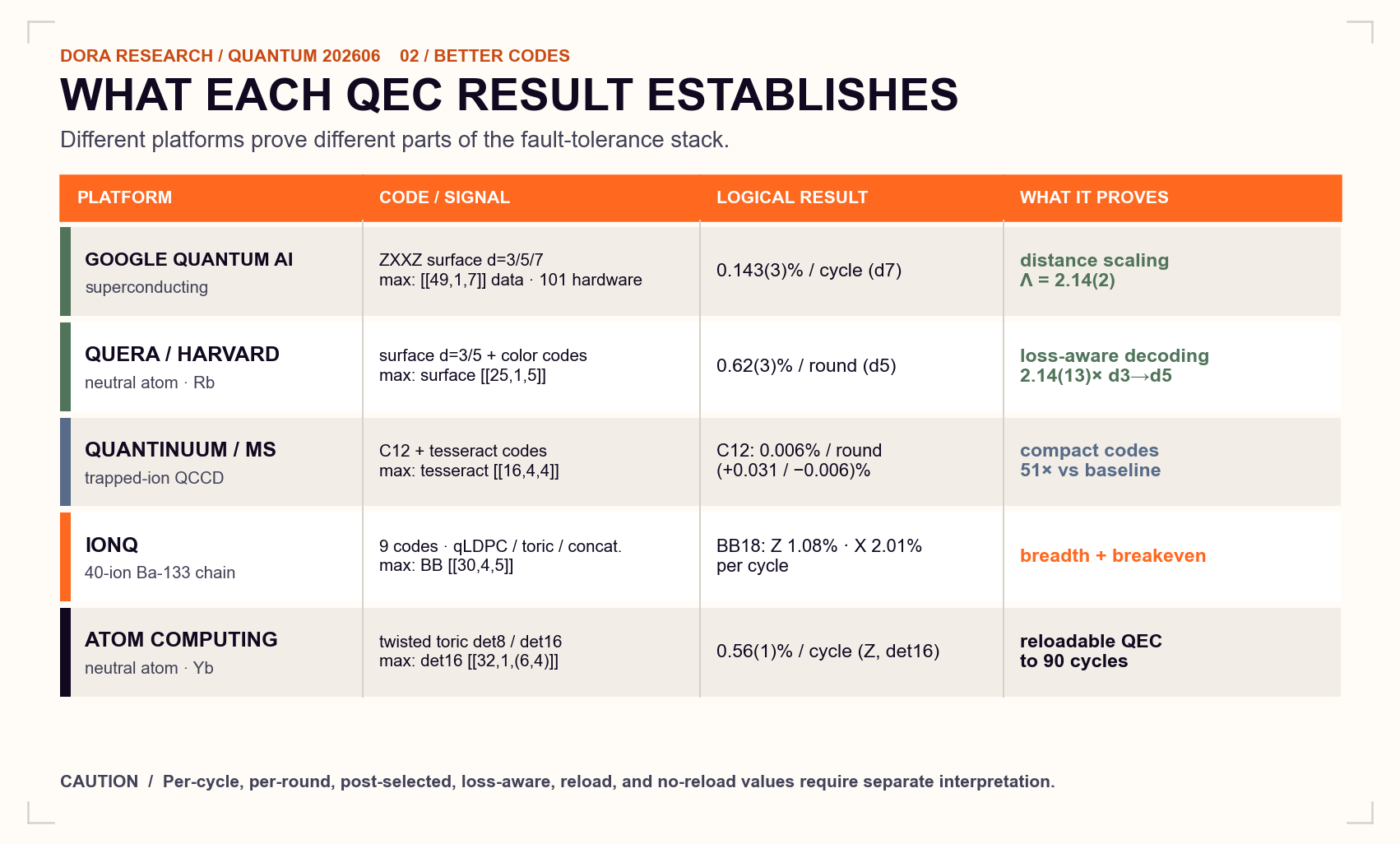
What the comparison establishes
Putting Google, QuEra/Harvard, Quantinuum/Microsoft, IonQ, and Atom Computing into one table creates an obvious temptation to rank them by logical error rate. That would be misleading.
The rows use different definitions: per-cycle and per-round errors, post-selection, loss-aware decoding, reload and no-reload operation, and different physical and logical tasks.
A better comparison asks what each experiment establishes:
- Google Quantum AI provides the cleanest distance-scaling, below-threshold result.[8]
- QuEra/Harvard demonstrates loss-aware decoding and key components of afault-tolerant neutral-atom architecture.[9]
- Quantinuum/Microsoft obtains very low logical circuit errors with compact trapped-ioncodes.[10]
- IonQ demonstrates code breadth and qLDPC breakeven on one platform.
- Atom Computing demonstrates sustained, reloadable neutral-atom QEC.
The table captures a set of fault-tolerance strategies that are finally becoming measurable. Their metrics remain too different for a single platform ranking.
4. Randomness Amplification
The gate and code papers are about preventing a quantum system from making mistakes. The ETH Zürich experiment uses quantum nonlocality to amplify weak randomness beyond what classical post-processing can guarantee under the same source assumptions.[7]
From weak inputs to amplified randomness
Real random sources are imperfect. Their outputs can be biased, and the bias can depend on previous outputs. Conventional extractors can remove many forms of noise. Classical post-processing alone cannot guarantee near-uniform output from a source that satisfies only the weaker Santha-Vazirani condition.
The ETH experiment uses weak random inputs to select Bell-test measurement bases. The Bell outputs and an independent seed are then passed to a two-source extractor. The security claim comes from a loophole-free Bell violation, which reduces dependence on the hardware's internal calibration.
The apparatus consists of two superconducting transmons housed in separate dilution refrigerators and connected by a 30-metre cryogenic microwave waveguide. It runs at 50 kHz for under eight hours of data acquisition, completing 1.342×10^9 trials and obtaining S_obs = 2.271. With an input bias of μ = 0.75%, the measurement-dependent-locality statistic remains positive. The protocol ultimately extracts 45,025,658 certified bits from 5,368,709,120 weak bits, with a security parameter of 10^-12.
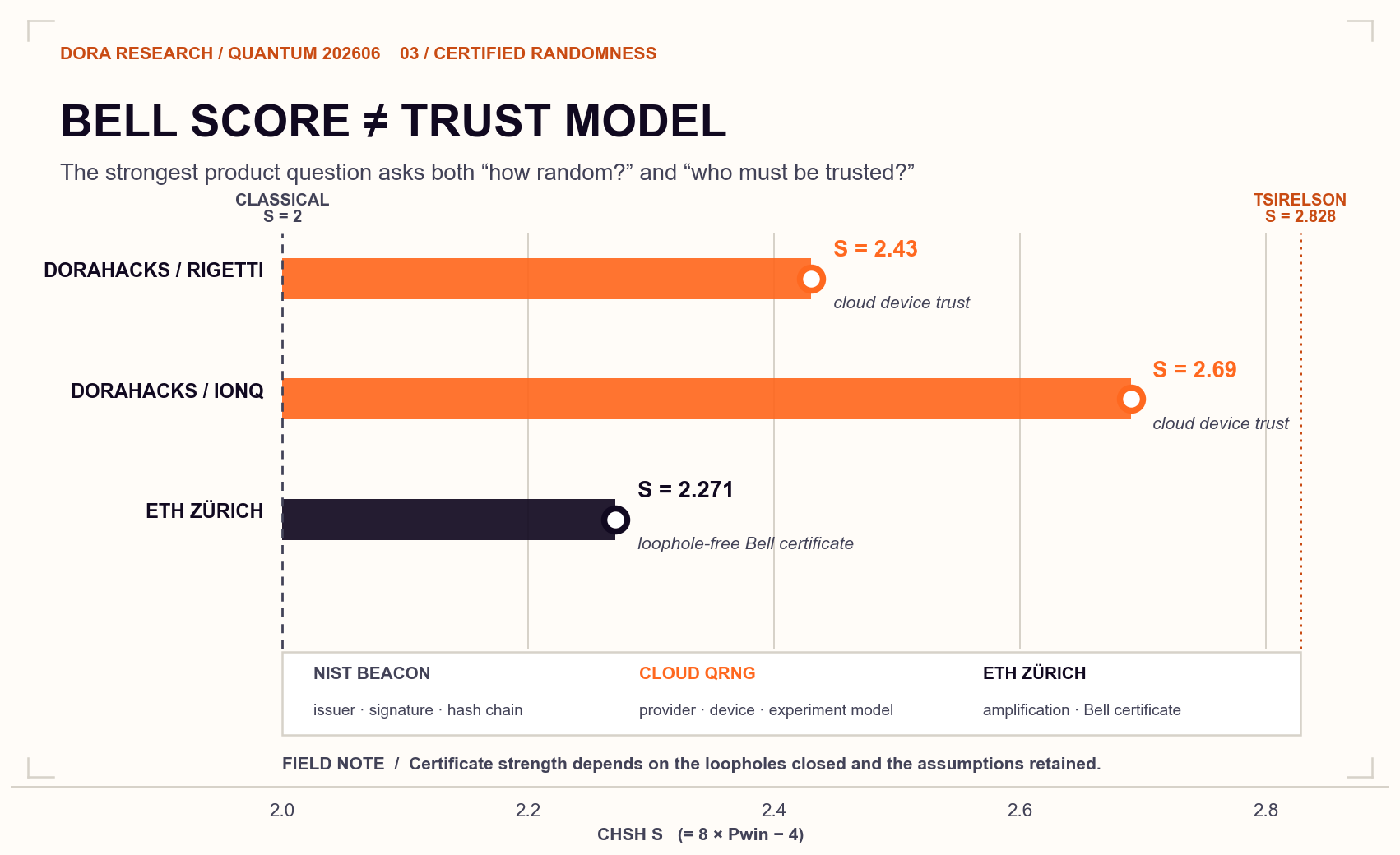
Bell score and certificate strength measure different things
In 2024, DoraHacks ran Bell-certified QRNG experiments on Rigetti Aspen-M-3 and IonQ Aria-1 through public cloud access.[11] On a common CHSH scale, S = 8P_win - 4, the two experiments produced values of approximately 2.43 and 2.69. Both are higher than ETH's 2.271.
The raw Bell score captures only one part of the certificate. In the cloud experiments, locality, detection, and other loopholes remain open, so the user still trusts the device, provider, and access model. ETH records a lower score. Space-like separation, carefully designed timing, high-efficiency measurement, and explicit treatment of memory effects support a stronger device-independent claim.
A useful comparison starts with each product's trust anchor, then considers throughput and the Bell score:
- NIST Randomness Beacon: trust the issuer, signature, and hash chain.
- Cloud QRNG: trust the quantum device, provider, and experimental model.
- ETH randomness amplification: trust the Bell certificate and its stated physicalassumptions.
For lotteries, MACI voting, leader election, fair ordering, and ZK soundness, the question “who must the user trust?” is part of the product specification. The ETH apparatus remains far from a commodity random-number service. Its central attraction is the shared physical origin of the useful output and its certificate.
5. Conclusion
Several layers of a fault-tolerant quantum system are beginning to take shape at the same time:
- Better gates: Harvard pushes peak fidelity, Princeton makes calibration more robust,and USTC sustains high-quality gates through mid-circuit refresh.
- Better codes: IonQ turns qLDPC into a platform benchmark, Atom Computing movesneutral-atom QEC toward continuous operation, and Google changes the resource curvethrough denser logical memory.
- Randomness amplification: ETH combines a loophole-free Bell test, weak randomness, andan extractor into an experimental system whose output is useful and whose certificate isintrinsic.
Q-day remains impossible to date from this set of papers. Their results show why every serious resource estimate needs explicit versioning. Gate error, code rate, decoding, reload, reaction time, and memory hierarchy are all moving. A fixed number copied from an old estimate will age quickly.
For Web3, randomness amplification remains the most immediate direction to develop. The useful next step is a continuously maintained trust ledger comparing randomness sources by assumptions, availability, latency, cost, and public verifiability.
6. References
- Lin, R. et al. “Sustaining high-fidelity quantum logic in neutral-atom circuits viamid-circuit operations.” arXiv:2603.01612 (2026).https://arxiv.org/abs/2603.01612
- Evered, S. J. et al. “High-fidelity entangling gates and nonlocal circuits with neutralatoms.” arXiv:2604.25987 (2026). https://arxiv.org/abs/2604.25987
- Liu, G. et al. “High-fidelity neutral atom gates leveraging low-rank Hessian optimization.”arXiv:2606.05060 (2026). https://arxiv.org/abs/2606.05060
- Tham, E. et al. “Breakeven demonstration of quantum low-density parity-check codes.”arXiv:2606.06455 (2026). https://arxiv.org/abs/2606.06455
- Atom Computing and Collaborators. “Quantum error correction with the toric code.”arXiv:2606.04079 (2026). https://arxiv.org/abs/2606.04079
- Low, G. H. et al. “A Denser Planar Surface Code.” arXiv:2605.30455 (2026).https://arxiv.org/abs/2605.30455
- Kulikov, A. et al. “Experimental randomness amplification.” Nature 653,1033-1038 (2026). https://doi.org/10.1038/s41586-026-10521-8
- Google Quantum AI and Collaborators. “Quantum error correction below the surface codethreshold.” Nature 638, 920-926 (2025).https://doi.org/10.1038/s41586-024-08449-y
- Bluvstein, D. et al. “A fault-tolerant neutral-atom architecture for universal quantumcomputation.” Nature 649, 39-47 (2026).https://doi.org/10.1038/s41586-025-09848-5
- Paetznick, A. et al. “Improved quantum processor logical error rates via correction anddetection.” Nature 654, 349-355 (2026).https://doi.org/10.1038/s41586-026-10628-y
- DoraHacks Frontier. “Realization of Bell’s theorem certified quantum random numbergeneration using cloud quantum computers.” Dora Research Blog (2024).https://research.dorahacks.io/2024/04/14/bell-theorem-certified-qrng-using-cloud-quantum-computers/