Review and discussion with Erica Grant and Eric Zhang
This is a progress report following an initial attempt from the Yale University's YQuantum Hackathon on AI-inspired quantum computer classifier based on QRNG data. The latest results can be found on the project's GitHub repo.
Overview
This research article details the Dora Quantum Computing Research Team's current work for our quantum random number generation (QRNG) project. Specifically, we explore how we generated QRNG data from various sources and using different methods, and then delve into our efforts to classify QRNG data both by source and by quantum vs classical RNG with maximum accuracy using machine learning models and data pre/post processing. We end with a discussion regarding the implications of our results so far, as well as how it all ties into the ultimate goal of producing noise-adjusted and verifiable quantum random numbers.
Introduction
Quantum Computing is poised to undergo a rapid transformation in scale and usage over the next years, and already, big tech companies, startups, and academic institutions are producing utility-scale quantum computers approaching 100+ qubits. One of the main effects of the standardization of error-corrected quantum computing is the effect it will have on encryption, cryptography, and general network security. Currently, encryption and all other use cases requiring random number generation, such as for use in scientific experiments, most commonly use classical pseudo-random number generation (PRNG) that perform complex transformations on inputted seeds to produce RNG output. However, classical encryption using PRNG has increasingly proven to be vulnerable to malicious attacks utilizing massive computing power to guess seeds and encryption output, and quantum computing will only exacerbate that problem. Furthermore, PRNG will always be limited by its deterministic nature, so quantum based random number generation, which is (hypothetically) "truly" random and thus has maximum entropy amongst all systems, offers a signficant upgrade for any use case in web3, cryptography, or other realms needed random numbers.
However, while still an upgrade over PRNG, current quantum systems are nowhere near to being perfect, leading us into the next section.
Quantum Noise Characterization
If current quantum computers were fault-tolerant and perfectly represented underlying quantum mechanical states, it would be impossible to classify QRNG output based on quantum device. PRNG vs QRNG classification would also be much more difficult, even with the best performing and most optimized machine learning models (it is important to note however that we could still use ancillary qubits to detect errors and correct them in the post-processing stage as quantum computing continues to advance).
However, we are currently in what is called the "Noisy intermediate-scale quantum" (NISQ) era of quantum computing, which essentially means that current quantum processing units (QPUs) are not fault tolerant and have measurement and gate errors for individual qubits and combinations of qubits ("qubit crosstalk"). "Quantum noise," as this phenomenon is called, occurs for a multitude of reasons, the most common being when physical realizations of quantum systems, such as superconducting qubits, are exposed to environmental interference. The diagram below visualizes quantum noise, or error, in a lattice based scheme.
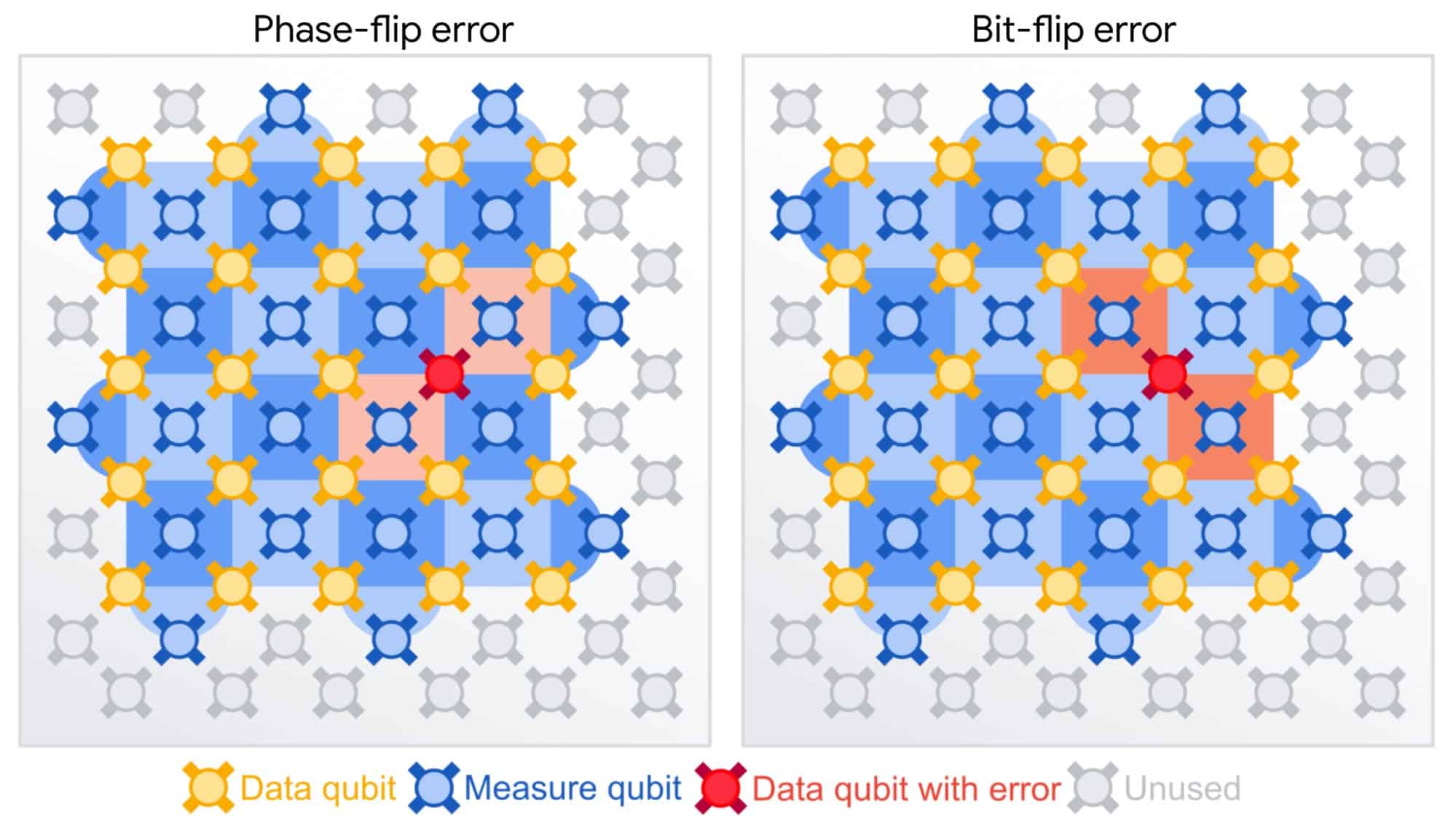
Given this bias, then, we can theoretically train models to distinguish between the output measurement data of different quantum computers, as well as between PRNG and QRNG data, by extracting features that characerize the small differences between qubit measurements in modern QPUs that result from quantum noise. High prediction accuracy would result in a two-fold advantage: the ability to estimate the source of QRNG data, as well as validate whether random number data is quantumly or classicly generated.
Data Preprocessing Methods
In order to move beyond just a basic training dataset with only individual qubits as features, we appended statistical measures generated off of each sequence of bits to our training data in an effort to characterize quantum noise using classical statistical measures. These tests helped measure the randomness of each sequence of bits. By taking a look at what we are trying to predict or learn with our models, we see that we need to be able to mark the unique errors generated by the quantum computers. Thus each statistical test in some way measures the randomness of the bit sequence - which should be unique to the computer and meaningfully different when compared to classically generated PRNG.
NIST Testing Suite
Most of the statistical tests we implemented were taken from and can be found in NIST's statistical testing suite.
The below is each measure we used as features when training our models.
Min-Entropy is a measure of how predictable the most predictable outcome is. It is given by:
where we are looking for the min entropy of
Shannon Entropy is the measure of unpredictability on average for a set of outcomes. Given by the formula:
where
Linear Correlation is another measure of randomness. Our simplified function breaks the sequence down and measures the position of the final "1". It then sums all of those positions and divides it by sequence length and block size.
Frequency involves counting the number of 1's and 0's. We then calculate the test statistic s, and then the p value is calculated using the error function erfc. This is a standard test to determine the randomness of a binary string.
Spectral test aims to detect patterns or peaks that would show non-randomness. Our spectral test is a simplified version. We first transform the data into an array of -1 and 1s, which allows us to use the Fast Fourier Transform to the bit array. Then it calculates the magnitude of half of the Discrete Fourier Transform, calculates the threshold, and using the magnitude, we can find how many peaks are under threshold. After this we compare with an expected number of peaks under threshold to calculate a test statistic d, which then we add to our dataframe as a feature. If there are bits causing errors, they will clearly add peaks to the data, and now the dataset contains that information.
Entropy rate is a measure of the uncertainty of the next bit in the sequence, given the previous k bits. We use a sliding window to measure conditional probability. We use the formula:
where
Autocorrelation is a simple test that compares the original bit sequence with a sequence that is lagged or shifted, which in our case was just 1 bit. A high autocorrelation (near 1 or -1) means that the lagged version was similar to the original, so there is some nonrandomness, while a value near 0 indicates randomness.
Qubit localized feature extraction
We also extracted similar features when training on our 100 qubit circuit dataset, detailed in the results section, but for each individual qubit instead of for the bitstring as a whole.
Initial Datasets & Progress with Simulated Data
The first dataset that we recieved during the Yale Quantum Hackathon from DoraHack's prior work on this topic was composed of simulated binary data generated through Qiskit. It had three labels - simulator, IBM-Lima, and IBM-Manila, the latter two respresenting device specific simulators with the appropriate noise models. We also generated a dataset of binary numbers from Rigetti's quantum computer, generated through the bell inequality "CHSH game" method for QRNG generation. The simulated data training dataset also generated data using the CHSH method. Our inital tests with these datasets was to simply distinguish between the different QRNG sources. the inital benchmark, with no preprocessing or model optimization was roughly around 50% - this was passing the IBM simulator data through classic models such as Random Forest and Gradient Booster, as well deep learning methods such as MLP and LTSM. Below is the workflow used for Bell's theorem certified QRNG, as well as visualizations of the circuits used in the process:
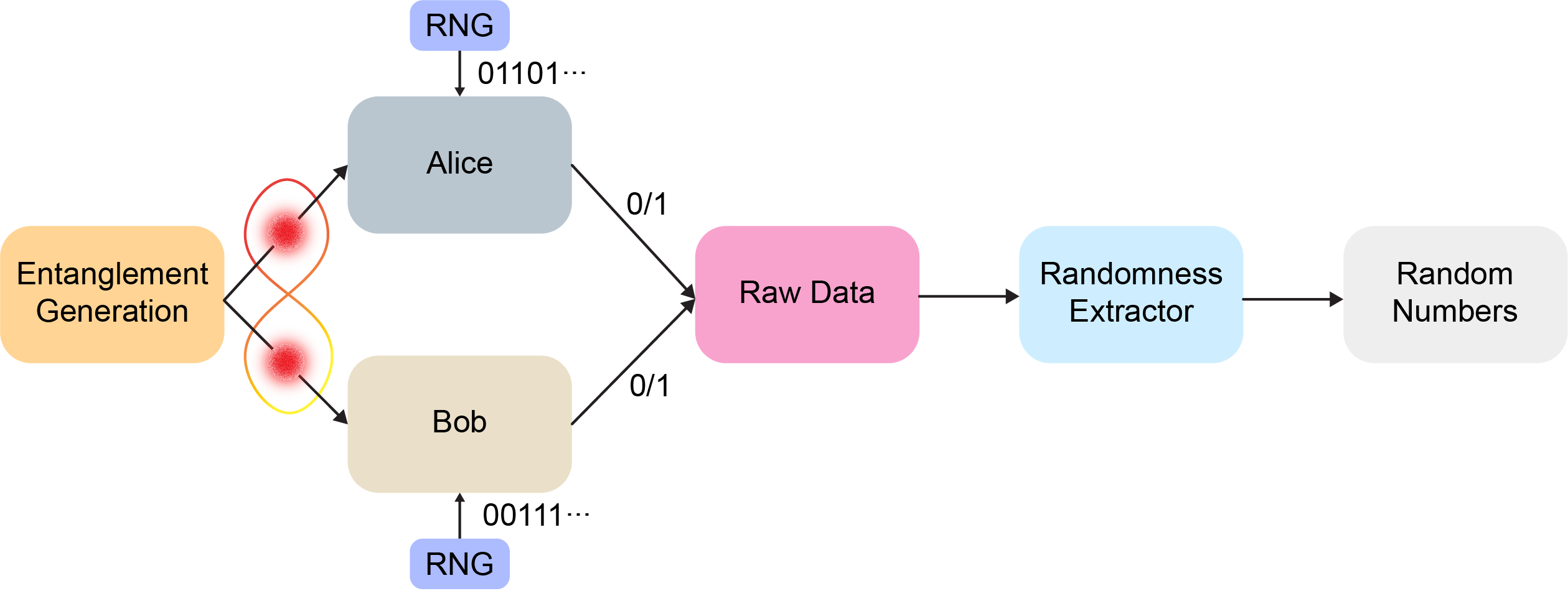
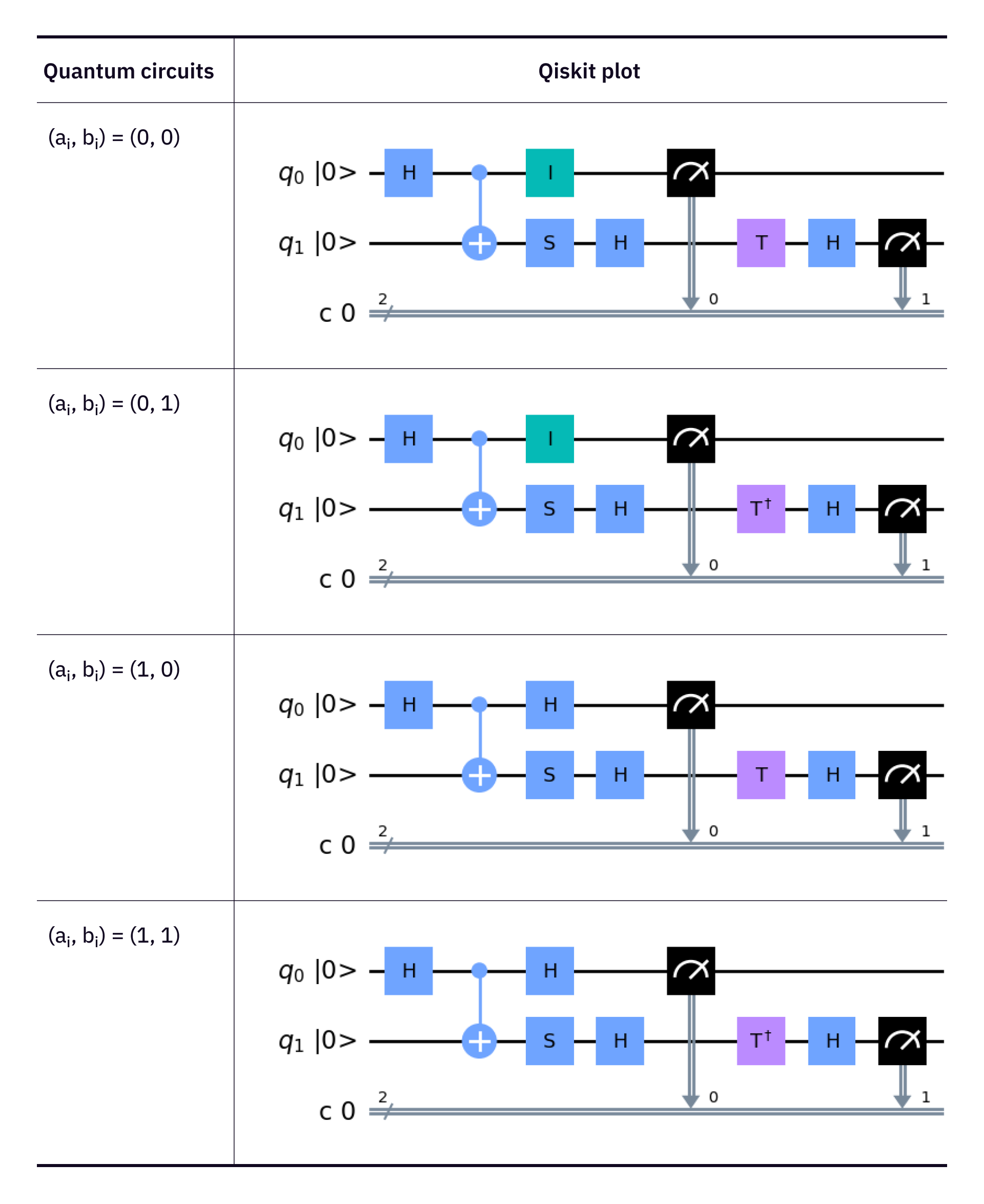
We next decided to use the preprocessing features we defined above to try and distinguish the different sources. Additionally, we appended the Rigetti data as a fourth source. We first applied three preprocessing tests - Shannon entropy, min entropy, and the spectral test. We only saw single digit percentage increases in classification accuracy at first, so we experimented with concatenating the data. This would allow the statistical tests to be calculated on longer strings of data, and in turn boosted our QPU classification up to nearly 78% with input lengths of 400 bits of data, instead of the original 100. With this dataset, our highest accuracy came from the Gradient Booster model, with the Random Forest model having slightly lower accuracy and neural networks impractical for this scope of data (see YQuantum Hackathon BUIDL).
As we spent time with the dataset, we were able to identify several patterns in our experiments. We noted that because the Rigetti dataset was so large in comparison to the simulator data (and perhaps because it was actual quantum data as compared to the simulated data of each other label), it was creating an unbalance in the dataset, which was skewing model performance. Additionally, when we tested with new CHSH-generated data from the IBM simulators, we found that our models struggled with that circuit in general, and couldn't meaningfully distinguish between QPUs. We also noted that the data from the simulator with no noise model incorporated was difficult for the model to classify. Once we removed it from the dataset, we saw significant gains in accuracy, which confirmed our guesses that the model needs the noise created by quantum errors to be able to classify the bits, which of course we were ultimately aiming to include with real QRNG data.
After testing model accuracy excluding both the Rigetti data and the simulator without noise, we moved on to focus on creating a more sophisticated training dataset generated solely with actual quantum computers. Given the comparative ease of use and reliability compared to all other publicly available quantum computers such as from IonQ and Rigetti, we decided to generate QRNG data using IBM QPUs, given that current IBM systems have 100+ reliable qubits and multiple different IBM QPUs are publicly accessible, allowing us to classify based on specific quantum computer. Additionally, we discarded the CHSH game as a method to generate QRNG data, given both its complexity to implement and the fact that using this method removes some of the quantum noise effects present in the training data, making classification and validation before post-processing more difficult.
QRNG Training Data Set Generation
Superposition Circuit
Our ultimate goal for the classifier, of course, was to train the model on QRNG data generated from real quantum computers in order to take advantage of existing quantum noise present in current-day quantum systems to classify QRNG data. To do this, we created training data sets by running circuits through IBM's instance, publicly accessible quantum computers using Qiskit, IBM's quantum computing Python SDK. IBM QPUs are the industry-leading quantum compters in terms of both qubit count (100+) and reliability, and they are relatively easy to access. The circuit we ran was relatively simple, putting qubits in a "superposition" of 0 and 1 basis states using Hadamard "H-gates" and then measuring each qubit. A diagram of a sample qubit in this circuit is shown below, generated with Qiskit:
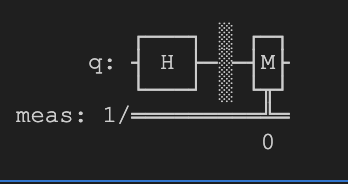
We expanded this circuit to 4 or 100 qubits (for two different datasets) and then ran it continously through 4 different IBM QPUs, storing the measurement results of each quantum job in order to create a sufficiently large dataset for model training. As seen below, we used the 4 qubit superposition data when comparing and classifying with quantum volume circuits, which also used 4 qubits, and when we moved on to attempting to classify quantum noise solely with the superposition QRNG data (for reasons explained below), we used the data generated with the 100 qubit circuit.
Quantum Volume Circuit
We also generated QRNG data through IBM QPUs using a different method - quantum volume circuits. Quantum volume circuits are most commonly used to measure the capacity of a quantum system by testing how many different combinations of multi-qubit gates the system can support, but they can also be used, as well as other similar circuits, to product QRNG data that reflects device-specific quantum gate error as well as individual qubit error. Below is the circuit we used (with the same seed each time to generate the same circuit) to generate the QV QRNG data:
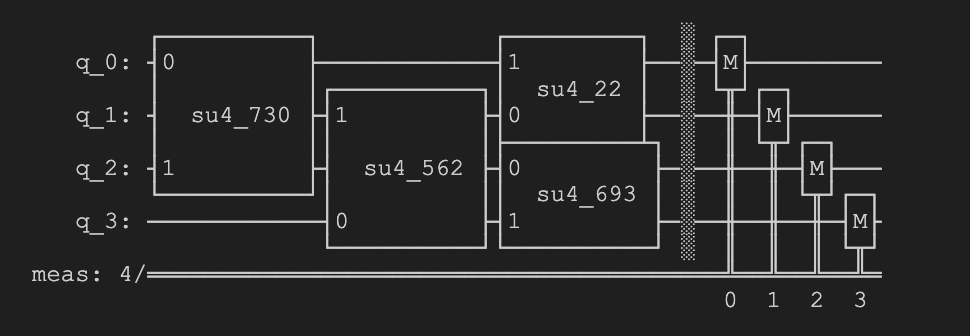
The notebooks we used to connect to IBM quantum backends, run the circuits, and store the measurement results are all in the GitHub repo linked in the appendix of this article.
Results
The following tables show the best model accuracies (as percent of testing data that the models predicted correctly) we obtained for a variety of classification tasks, model types, datasets, input lengths, and optimized preprocessing settings.
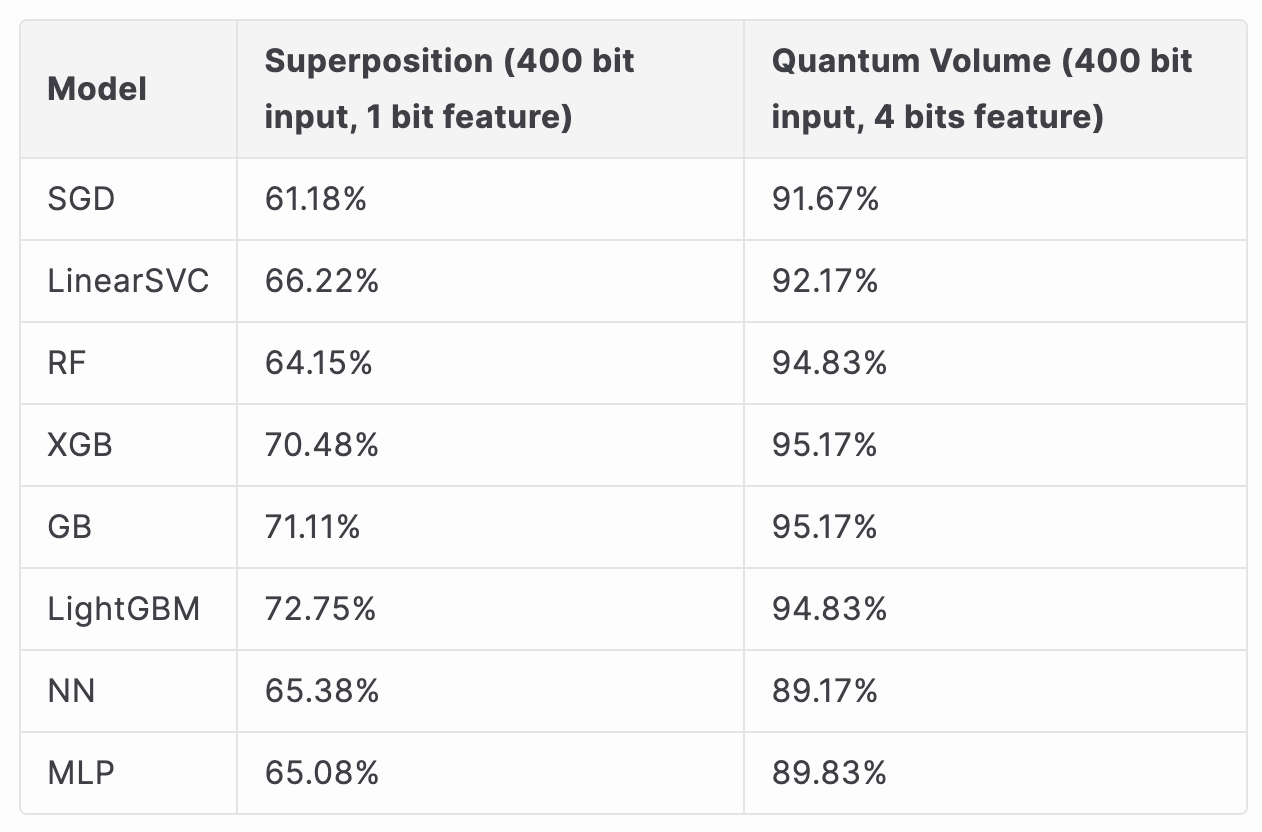
QRNG vs PRNG Classification
Benchmark accuracy (random guessing) = 50%
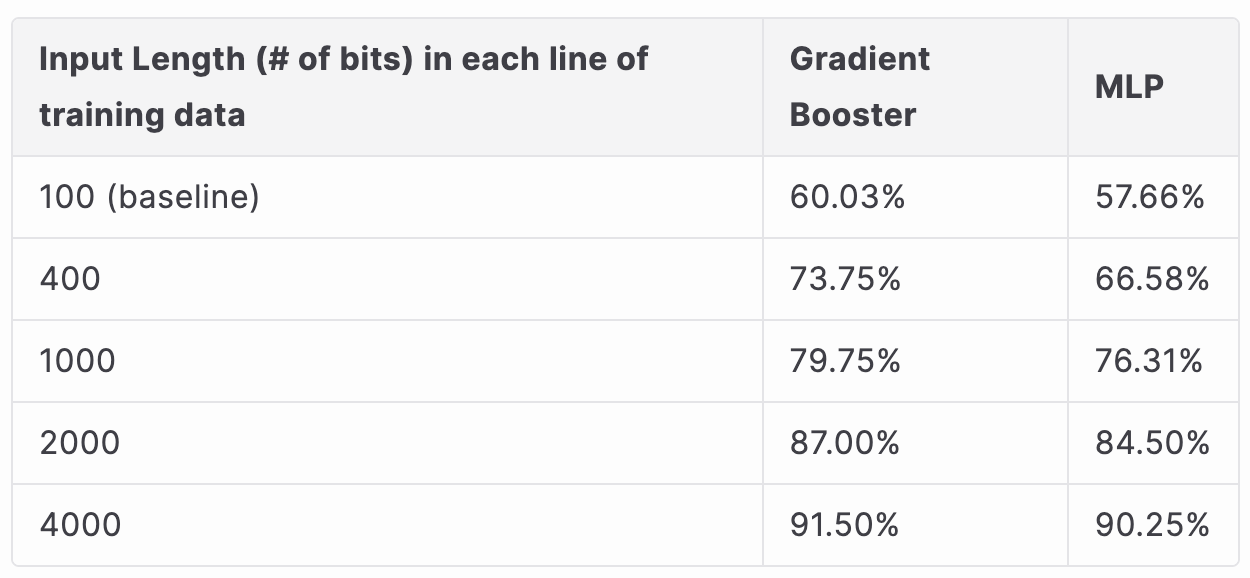
Next, we tested the best performing models for various settings (MLP and Gradient Boosting) on the 100 qubit superposition generated training dataset. At this stage in the process, we figured out that isolating individual qubit measurements and extracting features from them maximized prediciton accuracy by training on qubit-specific noise. So for example, with data generated from the 100 qubit circuit, if we set the model training data input length to 1000 bits, then each training data point would have 10 measurements from each qubit, for all 100 qubits. This allowed us to greatly expand our feature space by taking the same preprocessing feature extraction methods used above and applying them to each individual qubit's measurements.
QRNG vs PRNG Classification, 100 qubit superposition circuit
Training dataset size (with 100 bits per line) = 80000 lines (40000 lines of QRNG data from 4 IBM QPUs and 40000 lines of PRNG data)
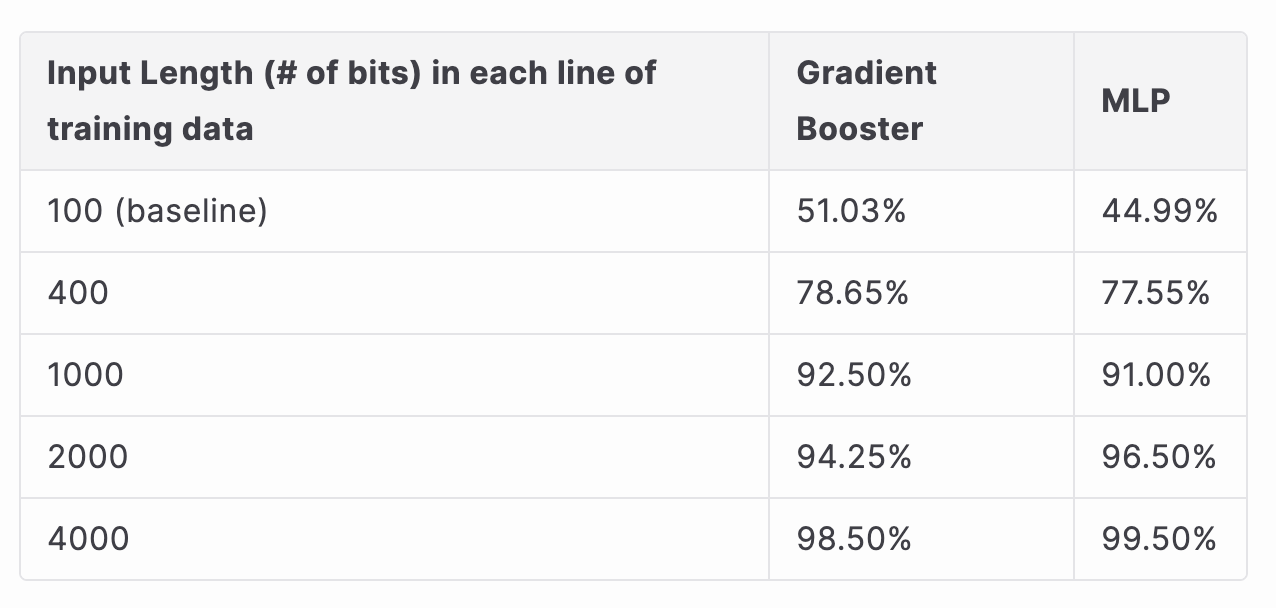
QPU Classification, 100 qubit superposition circuit
Training dataset size (with 100 bits per line) = 40000 lines (40000 lines of QRNG data from 4 IBM QPUs). Pure random guessing accuracy is 25% for 4 labels.
Discussion of Results and Possible Interpretations
QRNG vs PRNG Classification with Quantum Volume and Equivalent 4-qubit Superposition Circuits
Based on the data above, the model is able to classify both circuits, with the quantum volume circuit classification reaching over 95%, and superposition reaching nearly 73%. We believe that there are couple of possible explanations for this discrepancy. First, the quantum volume circuit has more gates and seems to be able to induce clearer error. However at the same time, the gates affect the measurements, and there is not a fair measurement, so its possible that the model is able to learn the circuit pattern rather than the noise. Superposition on the other hand is very similar to PRNG, so the model isn't always able to distinguish the difference between the two. With this in mind, quantum volume circuits might not be the best for unbiased classification tasks, but might prove useful for advanced quantum noise characterization by both gate and qubit errors, one of our future project aims.
100 qubit superposition circuits and qubit-specific feature extraction preprocessing
After evaluating the results of the previoud dataset, we moved on to training our supervised learning models with the 100 qubit superposition QRNG dataset. In order to measure how increasing the measurements per qubit in each trainning data line improved our accuracy results, we tested our optimized models with differing input lengths, with 100 bits corresponding to 1 measurement per 1 qubit. Some interesting results emerged, notably that accuracy did in fact significantly improve with longer input lengths (even more than when we increased the input size when training with the superposition VS QV dataset). The accuracy was only nominally better for the new dataset when classifying by PRNG VS QRNG, but was much more accurate for classifying by individual QPU, especially with longer input lengths. This seems to imply that most of the quantum noise when generating QRNG data is in fact from individual qubit measurement errors as a result of imperfect hardware, evidenced by the high classification accuracy when we were able to extract features from many measurements of the same qubit for each QPU.
Research Challenges and Next Steps
Broad-level Next Steps
- Deploy functional model(s) endpoints for multi-layered classification of raw input string QRNG data
- Integrate API we developed for QRNG output and Classifier into one packaged solution
- Continue work characterizing device specific quantum noise and qubit error rates for both increasing model accuracy and improving QRNG postprocessing
- Create a centralized analysis with visualizations of noise research
- Look into alternate techniques for pre-processing and post-processing
- Expand classifier models to work on general QRNG data, if feasible (more quantum computers and perhaps for arbitrary circuits)
- Run same currently deployed models on other quantum computing hardware to examine differences in prediction and classification accuracy
- Integrate refined QRNG generation practices into encryption practices and other use-cases for open source and web3 partners
Project Research Challenges
- Is it possible to achieve high classification accuracy with shorter input strings approaching 100 bits?
- Or more generally, with input string lengths that involve only one shot per qubit used
- Would require extracting device specific information about interactions between qubits in the system and measurement errors as a whole, rather than the current strategy of extracting measurement statistics from the results of each individual qubit in a longer input string
- Is it possible to achieve high classification accuracy when the number of qubits used in the QRNG circuit is unknown? In other words, when the number of qubits used in both training and testing data is variable and unknown.
- How can we use statistics such as qubit decoherence, qubit crosstalk, qubit-specific measurement errors to further improve our classification models?
- Is it possible to create (theoretically) cryptographically impenetrable protocols using QRNG combined with our post-processing, randomness extraction techniques?
- How can we use quantum noise/error characteristics to accomplish this?
- How can we deploy the API and our tested models in way that is most beneficial to partners and clients?
Appendix
- Link to GitHub repo
- Contains source code for all datasets, data generation scripts, and modeling experiment notebooks (with results) used and referenced in this article. More detailed documentation in repo. Feel free to recreate or reconfigure our experiments.
- Currently, we are contiously experimenting with new model builds, expanded QRNG data sets, and quantum noise characterization experiments as we aim to maximize classification accuracy, but we will consistenly push our latest work to this repo, and any eventual deployed models will have all their source code on the repo.